|
Rongkun Zheng I am a fourth-year (starting from 2022) Ph.D. student at the University of Hong Kong, supervised by Prof. Hengshuang Zhao. Before that, I received my B.Eng. from Tsinghua University in 2022. I've done internships with SenseTime, and Shlab. My research interests lie in the field of deep learning and computer vision, I've published multiple research works for video perception, open-world multi-modal learning, and video understanding. Now I have interests in MLLM and reinforcement learning. Update: On job market now! Drop me an email if you are interested. |

|
|
|
|
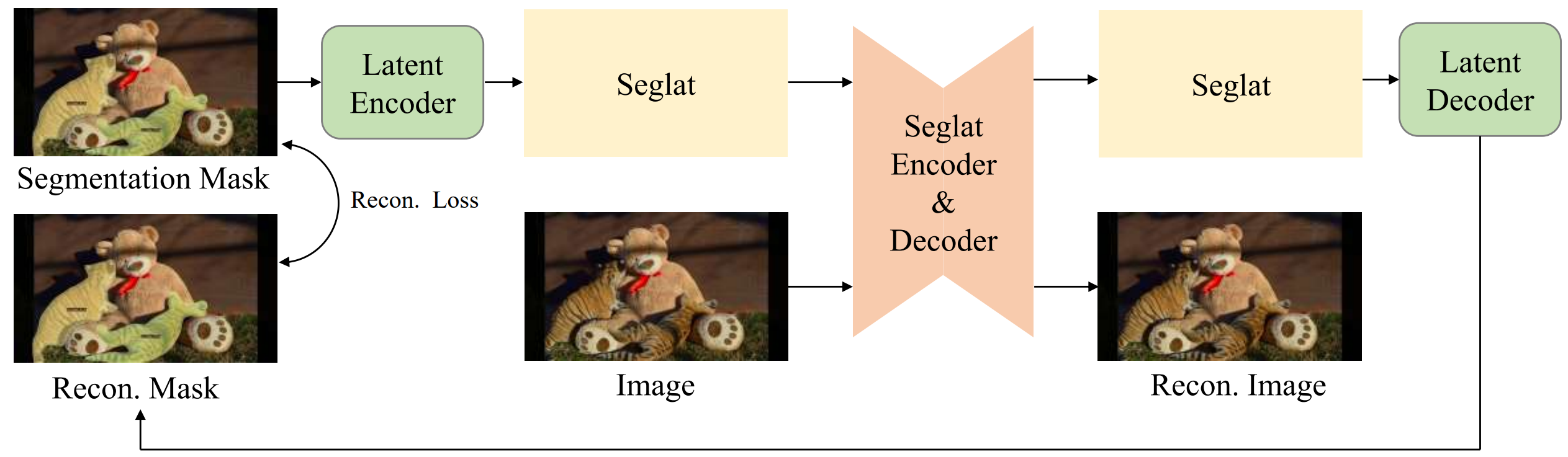
Rongkun Zheng, Lu Qi, Xi Chen, Yi Wang, Kun Wang, Yu Qiao, Hengshuang Zhao NeurIPS, 2025 pdf / code We propose Seg-VAR, a novel framework that rethinks segmentation as a conditional autoregressive mask generation problem. This is achieved by replacing the discriminative learning with the latent learning process. |

|
Rongkun Zheng, Lu Qi, Xi Chen, Yi Wang, Kun Wang, Yu Qiao, Hengshuang Zhao ICCV, 2025 pdf / code Our ViLLa is an effective and efficient LMM capable of segmenting and tracking with reasoning capabilities. It can handle complex video reasoning segmentation tasks, such as: (a) segmenting objects with complex interactions; (b) segmenting objects with complex motion; (c) segmenting objects in long videos with occlusions. |

|
Jiahe Zhao, Rongkun Zheng, Yi Wang, Helin Wang, Hengshuang Zhao ICCV, 2025 pdf / code We introduce DisCo, a novel visual encapsulation method designed to yield semantically distinct and temporally coherent visual tokens for video MLLMs. |
|
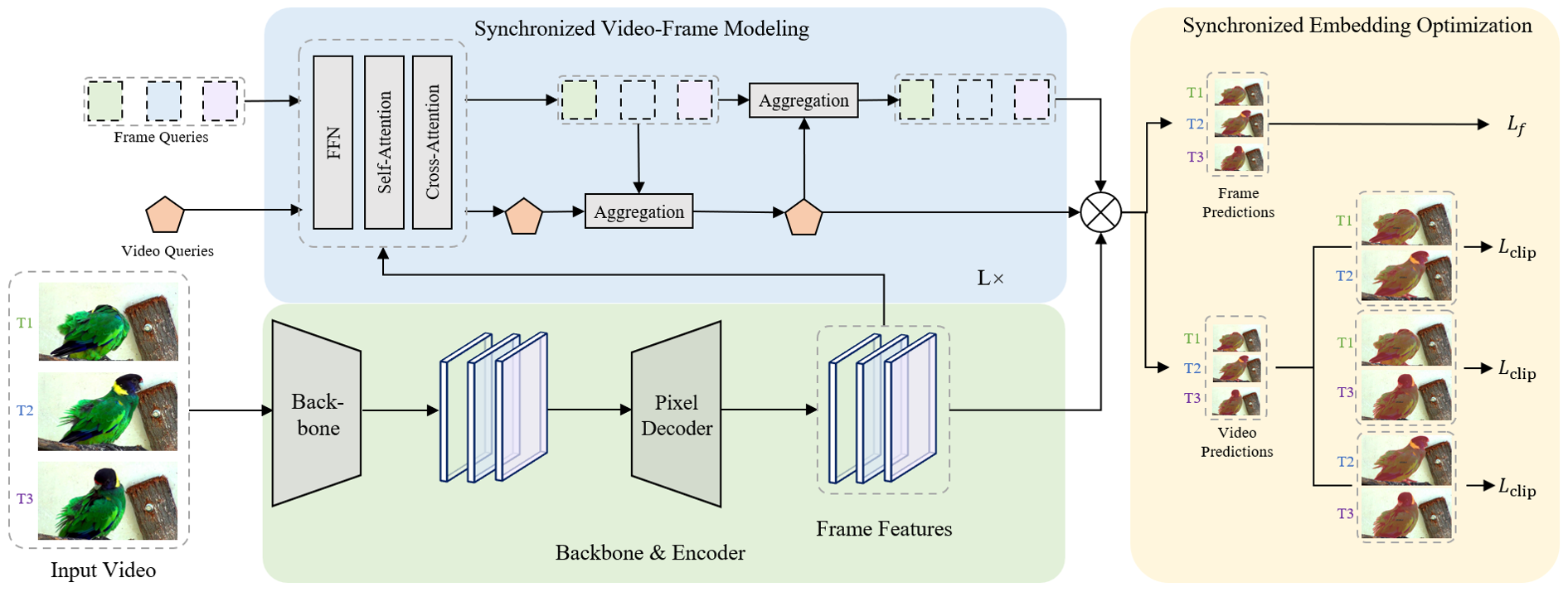
Rongkun Zheng, Lu Qi, Xi Chen, Yi Wang, Kun Wang, Yu Qiao, Hengshuang Zhao NeurIPS, 2024 pdf / code In this work, we analyze the cause of this phenomenon and the limitations of the current solutions, and propose to conduct synchronized modeling via a new framework named SyncVIS. |
|
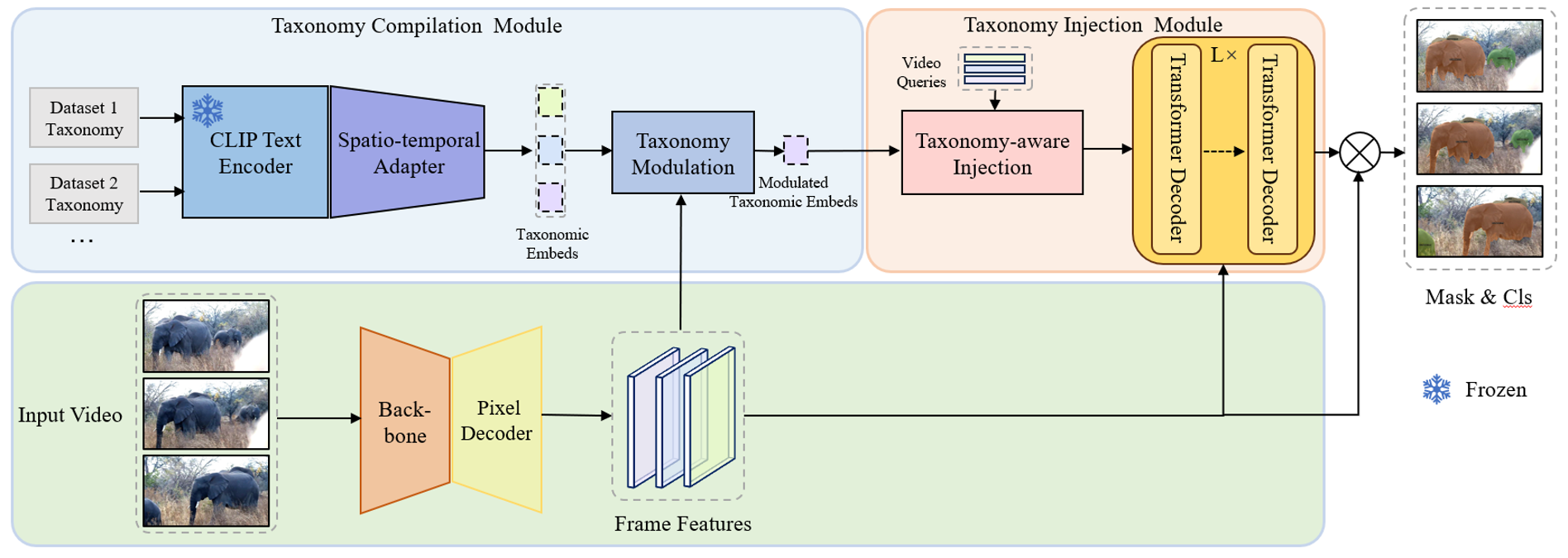
Rongkun Zheng, Lu Qi, Xi Chen, Yi Wang, Kun Wang, Yu Qiao, Hengshuang Zhao NeurIPS, 2023 pdf / code In this work, we analyze that providing extra taxonomy information can help models concentrate on specific taxonomy, and propose our model TMT-VIS, which is a taxonomy-aware multi-dataset joint training framework for video instance segmentation. |
|
Reviewer
Teaching Assistant
|
|
Design and source code from Jon Barron's website |